DMA란 무엇인가
1. DMA가 왜 필요한가
전통적인 I/O 모델에서 디바이스로부터 메모리로 데이터를 옮기는 일은 CPU의 몫이었다. CPU는 디바이스 레지스터에서 한 워드씩 읽어 메모리에 쓰는 일을 수만 번 반복해야 했고, 그 사이 CPU 사이클은 단순한 데이터 복사에 묶여 다른 일을 할 수 없다.
해결책은 단순하다. CPU를 거치지 않고 디바이스가 메모리를 직접 읽고 쓰게 한다. 이것이 Direct Memory Access(DMA)이다. Microsoft Learn의 정의를 그대로 옮기면, “DMA는 CPU를 우회하는 데이터 전송 전략이며, 전용 DMA 컨트롤러가 메모리와 디바이스 사이에서 데이터를 전송한다.” 드라이버 입장에서는 디바이스에 “이 메모리 범위를 읽어/써라”라고 한 번 지시한 뒤, 전송이 끝났음을 알리는 인터럽트만 기다리면 된다.
2. 두 가지 모델: 시스템 DMA와 버스 마스터 DMA
DMA를 누가 주도하느냐에 따라 두 모델이 있다.
시스템 DMA(system-mode DMA) 는 메인보드 또는 SoC 위에 있는 공유된 다채널 DMA 컨트롤러가 여러 디바이스의 전송을 대행하는 방식이다. ISA 시대의 8237 DMA 컨트롤러가 대표적이며, 현대 PC에서는 거의 자취를 감췄지만 SoC 기반 시스템(Windows 8 이상의 임베디드/모바일 플랫폼)에서 다시 중요해졌다. 이 모델에서 디바이스는 자체 DMA 컨트롤러가 없고, 다른 디바이스들과 공유 컨트롤러를 두고 채널을 할당받아 사용한다. 이러한 디바이스를 종속 디바이스(subordinate device) 라고 부른다.
버스 마스터 DMA(bus-master DMA) 는 디바이스 자신이 DMA 컨트롤러를 내장하고, I/O 버스의 사용권을 시스템과 직접 조정(arbitrate)하여 메모리에 접근하는 방식이다. 오늘날의 PCIe 디바이스는 거의 모두 이 모델을 사용한다. 버스 마스터 디바이스는 하나의 IRP에 대해 전송 시작/종료 시점을 드라이버가 알 수 있는지 여부에 따라 패킷 기반(packet-based) 과 Common Buffer (continuous DMA) 방식 중 하나(또는 둘 다)를 사용한다.
KMDF의 경우, Windows 7 이전에는 버스 마스터 DMA만 지원했고, Windows 8 이상의 SoC 플랫폼부터 시스템 모드 DMA를 함께 지원한다. PC 기반 플랫폼에서의 시스템 모드 DMA는 KMDF가 지원하지 않는다.
Note
현대의 PCIe 기반 가속기들 — GPU, NIC, NVMe, NPU 등 — 는 모두 버스 마스터 DMA에 해당한다. 시스템 DMA는 SoC 임베디드 환경이 아니라면 더 이상 마주칠 일이 거의 없다.
3. DMA를 둘러싼 세 가지 주소 공간
DMA를 수행하는 드라이버는 세 가지 주소 공간을 동시에 다루어야 한다.
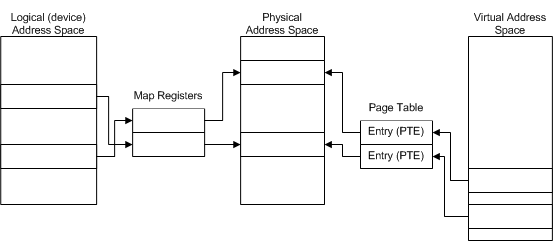
- 가상 주소 공간(Virtual Address Space): CPU(드라이버 코드)가 보는 주소. 32비트 프로세서에서는 4GB. CPU는 페이지 테이블(PTE)을 통해 가상 주소를 물리 주소로 변환한다.
- 물리 주소 공간(Physical Address Space): 실제 RAM 칩 위의 위치. 페이지 테이블이 가상→물리를 담당한다면, MDL(Memory Descriptor List) 이 드라이버 버퍼에 대해 같은 매핑 정보를 담는다.
- 논리 주소 공간(Logical/Device Address Space): 디바이스가 보는 주소. 이는 물리 주소와 일치할 수도, 다를 수도 있다. 맵 레지스터(map register) 가 논리→물리 변환을 담당한다.
세 공간은 서로 다른 주소 체계이므로, 드라이버는 가상 주소 포인터로 직접 물리 메모리를 가리킬 수 없고, 디바이스 또한 논리 주소만으로는 물리 메모리에 접근할 수 없다. 반드시 적절한 변환을 거쳐야 한다.
Note
정리하자면, 소프트웨어 측의 변환자는 “MDL + 페이지 테이블”이고, 하드웨어 측의 변환자는 “맵 레지스터”이다. 둘 다 결국 같은 일(주소를 물리 메모리로 변환)을 하지만, 보는 쪽이 다르다.
4. MDL: 가상 버퍼의 물리적 실체를 기록하는 자료구조
연속된 가상 주소 영역에 있는 I/O 버퍼라도, 물리 메모리에서는 여러 페이지에 흩어져 있을 수 있다(가상 메모리의 본질적 특성). MDL은 가상 버퍼가 실제로 물리 메모리의 어느 페이지들에 흩어져 있는지를 기록한 구조체이다.
MDL은 MDL 구조체 본체에 이어, 버퍼가 위치한 물리 페이지 번호 배열이 따라붙는 형태로 구성된다. 일부 필드(Next, MdlFlags)를 제외하면 모두 불투명하므로, 드라이버는 직접 접근하지 않고 다음과 같은 매크로/함수를 통해서만 다룬다.
MmGetMdlVirtualAddress: MDL이 설명하는 버퍼의 가상 주소를 얻는다.MmGetMdlByteCount: 버퍼의 크기를 얻는다.MmGetMdlByteOffset: 첫 페이지 안에서 버퍼가 시작하는 오프셋을 얻는다.
DMA 전송 직전에 드라이버가 MmGetMdlVirtualAddress를 호출하는 이유는, MDL의 인덱스를 후속 DMA 호출에 넘기기 위한 핸들로 쓰기 위해서이다.
5. 맵 레지스터: 디바이스에게 보이는 주소 만들기
MDL이 소프트웨어 측에서 가상→물리 매핑을 담당한다면, 맵 레지스터는 하드웨어 측에서 논리→물리 매핑을 담당한다. 둘은 같은 물리 주소 공간을 양쪽에서 바라보는 짝패이다.
디바이스마다 접근할 수 있는 주소 폭이 다르다. 예를 들어 ISA DMA 컨트롤러는 24비트 주소 라인밖에 없어 16MB 이상의 메모리에 직접 접근할 수 없다. 32비트 PC에서 RAM이 4GB까지 확장되면, 16MB 위에 있는 페이지로의 DMA 전송을 어떻게 처리해야 하는가? 반대로 PCI 디바이스는 보통 32비트(또는 64비트) 주소 라인을 가지므로 시스템 RAM 전체에 접근할 수 있다.
이 차이를 흡수하는 것이 맵 레지스터이다. HAL이 제공하는 (드라이버에는 불투명한) 자원으로, 디바이스가 접근 가능한 논리 주소를 실제 물리 페이지로 별칭(alias)한다.
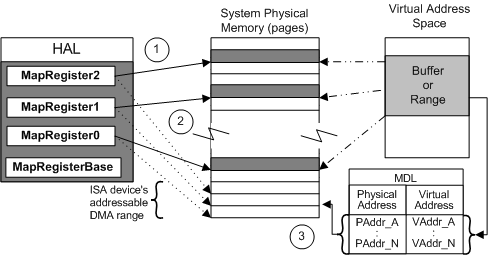
위 그림은 Scatter/Gather 능력이 없는 ISA DMA 디바이스의 사례이다.
- 세 개의 맵 레지스터(MapRegister0/1/2)가 시스템 물리 메모리 안에 흩어져 있는 세 개의 페이지를, ISA 디바이스가 접근할 수 있는 저순위 논리 주소 범위에 별칭으로 노출한다.
- ISA 디바이스는 이 논리 주소를 사용해 마치 자기가 직접 접근할 수 있는 영역인 양 메모리에 DMA를 수행한다.
- MDL은 같은 데이터를 가상 주소 ↔ 물리 주소로 매핑한다.
PCI DMA 디바이스의 경우에도 같은 수의 맵 레지스터가 사용되지만, 매핑된 논리 주소 범위가 반드시 물리 주소 범위와 동일할 필요는 없다. PCI 디바이스도 결국 논리 주소를 통해 메모리에 접근한다.
Important
맵 레지스터의 가장 중요한 부수 효과는 다음과 같다. 자신의 디바이스가 Scatter/Gather를 하드웨어적으로 지원하지 않더라도, 맵 레지스터가 사실상 Scatter/Gather 기능을 제공한다. HAL이 흩어진 물리 페이지들을 디바이스가 보기에 연속된 논리 주소 영역으로 묶어 주기 때문이다.
맵 레지스터의 실체는 플랫폼에 따라 칩 내부의 하드웨어 레지스터일 수도, 시스템 DMA 컨트롤러나 버스 마스터 어댑터 안의 레지스터일 수도, 심지어 HAL이 시스템 메모리에 만든 가상 레지스터일 수도 있다. 드라이버는 이 차이를 알지 못하며 알 필요도 없다.
x86/x64에서는 일반적으로 맵 레지스터가 거의 항등 매핑(identity mapping)이어서 실질적인 변환 비용이 작다. 반면 ARM/SoC 기반 시스템에서는 IOMMU와 결합되어 실제 변환과 보호 기능을 제공한다.
6. Scatter/Gather: 흩어진 메모리를 한 번의 전송으로
가상 주소 공간에서 연속된 32KB 버퍼라도, 물리 메모리에서는 8개의 4KB 페이지가 따로따로 흩어져 있을 수 있다. Scatter/Gather DMA는 디바이스가 이렇게 흩어진 여러 물리 페이지를 한 번의 DMA 동작으로 모두 처리할 수 있게 해 주는 기법이다. 방향 기준은 항상 호스트 메모리이다.
- Gather (호스트 메모리 → 디바이스): 흩어진 페이지에서 데이터를 모아(gather) 디바이스로 보낸다.
- Scatter (디바이스 → 호스트 메모리): 디바이스에서 들어온 데이터를 흩어진 페이지로 풀어 쓴다(scatter).
이 기능은 두 층에서 구현될 수 있다.
- 하드웨어 Scatter/Gather: 디바이스 자체가 (주소, 길이) 쌍의 리스트를 받아 각 영역을 차례로 처리할 수 있는 경우. 현대 PCIe 디바이스 대부분이 여기에 해당한다.
- 소프트웨어 Scatter/Gather: 디바이스는 한 번에 한 영역만 처리할 수 있더라도, 위에서 본 맵 레지스터 메커니즘 덕분에 HAL이 흩어진 물리 페이지들을 디바이스가 보기에 연속된 논리 주소로 별칭해 줄 수 있다. 결과적으로 디바이스는 자기가 Scatter/Gather를 하는지도 모른 채 동일한 효과를 얻는다.
WDM의 GetScatterGatherList/PutScatterGatherList 루틴, 그리고 KMDF의 DMA 트랜잭션 객체는 이 두 경우를 모두 동일한 인터페이스로 추상화한다.
7. Common Buffer: 디바이스와 드라이버가 공유하는 메모리
Common Buffer(또는 continuous DMA)는 단순한 개념이다. 드라이버와 디바이스가 같은 물리 메모리 영역을 동시에 매핑해 두고, 양쪽이 같은 영역을 들여다보면서 협력하는 방식이다. 한 번 할당하면 드라이버 수명 동안 유지되는 경우가 많다.
전형적인 용도는 다음과 같다.
- 메일박스(mailbox): 디바이스가 상태 정보를 쓰고 드라이버가 명령을 쓰는, 양방향 통신용 공유 영역.
- 디스크립터 링(descriptor ring): NIC, 스토리지 컨트롤러 등이 송수신할 패킷/블록의 메타데이터를 큐 형태로 주고받는 구조.
- 시스템 DMA 컨트롤러의 자동 초기화 모드용 버퍼: 같은 버퍼를 반복적으로 채워 넣어야 하는 오디오 같은 스트리밍 디바이스에 적합.
AllocateCommonBuffer는 두 종류의 포인터를 한꺼번에 반환한다. 드라이버가 사용할 가상 주소(VirtualAddress)와, 디바이스 프로그래밍에 그대로 넘겨줄 논리 주소(LogicalAddress)이다. 같은 물리 메모리에 대한 두 개의 시점이라고 보면 된다.
8. 캐시 일관성(cache coherency)
CPU는 메모리 접근을 가속하기 위해 데이터 캐시를 사용한다. 그런데 DMA 디바이스는 이 캐시를 우회하여 RAM에 직접 쓴다. 두 사실이 충돌하면 어떤 일이 벌어지는가?
- 디바이스 → 메모리 전송(읽기) 후, CPU가 캐시에 남아 있는 옛날 값을 다시 읽으면 새로 들어온 데이터를 보지 못한다. 따라서 전송 후 캐시 무효화(invalidate) 가 필요하다.
- 메모리 → 디바이스 전송(쓰기) 전에, CPU가 캐시에만 써 두고 아직 RAM에 반영하지 않은 데이터가 있으면 디바이스가 오래된 값을 읽게 된다. 따라서 전송 전에 캐시 플러시(flush) 가 필요하다.
이 문제는 플랫폼마다 다르게 처리된다.
- x86/x64: 하드웨어가 캐시 일관성을 보장한다. 드라이버가 명시적으로 플러시 호출(
KeFlushIoBuffers)을 해도 사실상 no-op이다. - ARM/SoC: 하드웨어 일관성이 보장되지 않는 경우가 많아, 플러시/무효화를 명시적으로 호출해야 한다. WDM의
FlushAdapterBuffers/MapTransfer(또는 v3 인터페이스의…Ex변형들)가 이 일을 알아서 처리해 준다.
DMA 작업 인터페이스 v3에서는 MapTransferEx가 쓰기 전 플러시를, FlushAdapterBuffersEx가 읽기 후 무효화를 모두 보장하므로 KeFlushIoBuffers를 별도로 호출할 필요가 없다(오히려 ARM에서는 성능 저하 요인이 된다).
9. DMA Transaction과 DMA Transfer (KMDF 용어)
KMDF는 두 단어를 명확히 구분한다.
- DMA transaction: 하나의 완결된 I/O 작업. 응용 프로그램으로부터 받은 한 번의 read/write 요청에 대응한다.
- DMA transfer: 메모리와 디바이스 사이의 단일 하드웨어 전송 동작.
하나의 transaction은 항상 최소 한 번의 transfer로 구성되지만, transaction이 디바이스가 한 번에 옮길 수 있는 크기를 초과하면 Framework가 여러 개의 transfer로 쪼갠다. 이 구분이 중요한 이유는, KMDF의 콜백(EvtProgramDma 등)이 transfer 단위로 호출되기 때문이다.
10. IRQL: 대부분의 DMA 콜백은 DISPATCH_LEVEL이다
DMA 관련 지원 루틴과 콜백(AdapterControl, AdapterListControl, EvtProgramDma 등) 대부분은 IRQL = DISPATCH_LEVEL 에서 실행된다. 이는 다음을 의미한다.
- 페이지 폴트가 일어나면 안 된다 → 페이징 가능한 메모리에 접근하면 안 된다.
- 블로킹 호출(예: 커널 이벤트 대기)을 해서는 안 된다.
- 어댑터 객체 포인터 등 콜백에서 참조할 모든 데이터는 비페이지(nonpaged) 메모리에 저장해야 한다 — 그래서 디바이스 확장(device extension)이 단골 저장소가 된다.
실제 API 호출 시퀀스(AllocateCommonBuffer, GetScatterGatherList, …Ex 변형들 등)에 대한 정확한 레퍼런스는 MS Learn의 DMA Programming Techniques와 Version 3 of the DMA Operations Interface 페이지에 있다.
출처
참고한 Microsoft Learn 페이지들:
- Windows Kernel-Mode DMA Library — DMA의 정의와 Device Memory Access와의 차이
- DMA Programming Techniques — 한 줄 정의(“CPU를 우회하는 데이터 전송 전략”)
- Map Registers — 세 가지 주소 공간과 맵 레지스터 (본문의 두 그림 출처)
- Using MDLs — MDL의 정의와 매크로
- Introduction to Adapter Objects — 어댑터 객체와 종속/버스 마스터 구분
- Using Bus-Master DMA — 패킷 기반 vs Common Buffer
- Supporting System-Mode DMA — 시스템 DMA의 정의(KMDF)
- DMA Transactions and DMA Transfers — transaction/transfer 용어
- Framework DMA Objects — DMA enabler/transaction/common buffer 객체
- Version 3 of the DMA Operations Interface — 캐시 플러시 동작과 ARM 주의사항
- Getting an Adapter Object — IRQL과 비페이지 저장소 요구사항
더 깊이 다루는 자료:
- OSR Online —
osr.com의 NT Insider 아카이브에는 Windows DMA를 본격적으로 다루는 튜토리얼 글이 다수 있다. - Walter Oney, Programming the Microsoft Windows Driver Model (2판) — WDM/KMDF 시대의 DMA를 가장 체계적으로 설명하는 표준 텍스트.
- WDK 샘플
general/pcidrv— 실제로 동작하는 KMDF 기반 PCI NIC 드라이버. DMA 트랜잭션 객체 사용을 코드 단위로 볼 수 있는 가장 좋은 실례.